##前言
Github很好的将代码和社区联系在了一起,于是发生了很多有趣的事情,世界也因为他美好了一点点。Github作为现在最流行的代码仓库,已经得到很多大公司和项目的青睐,比如jQuery、Twitter等。为使项目更方便的被人理解,介绍页面少不了,甚至会需要完整的文档站,Github替你想到了这一点,他提供了Github Pages的服务,不仅可以方便的为项目建立介绍站点,也可以用来建立个人博客。
Github Pages有以下几个优点:
- 轻量级的博客系统,没有麻烦的配置
- 使用标记语言,比如Markdown 无需自己搭建服务器
- 根据Github的限制,对应的每个站有300MB空间
- 可以绑定自己的域名
当然他也有缺点:
- 使用Jekyll模板系统,相当于静态页发布,适合博客,文档介绍等。
- 动态程序的部分相当局限,比如没有评论,不过还好我们有解决方案。
- 基于Git,很多东西需要动手,不像Wordpress有强大的后台
大致介绍到此,作为个人博客来说,简洁清爽的表达自己的工作、心得,就已达目标,所以Github Pages是我认为此需求最完美的解决方案了。
##购买、绑定独立域名
虽说Godaddy曾支持过SOPA,并且首页放着极其不专业的大胸美女,但是作为域名服务商他做的还不赖,选择它最重要的原因是他支持支付宝,没有信用卡有时真的很难过。
域名的购买不用多讲,注册、选域名、支付,有网购经验的都毫无压力,优惠码也遍地皆是。域名的配置需要提醒一下,因为伟大英明的GFW的存在,我们必须多做些事情。
流传Godaddy的域名解析服务器被墙掉,导致域名无法访问,后来这个事情在BeiYuu也发生了,不得已需要把域名解析服务迁移到国内比较稳定的服务商处,这个迁移对于域名来说没有什么风险,最终的控制权还是在Godaddy那里,你随时都可以改回去。
我们选择DNSPod的服务,他们的产品做得不错,易用、免费,收费版有更高端的功能,暂不需要。注册登录之后,按照DNSPod的说法,只需三步(我们插入一步):
首先添加域名记录,可参考DNSPod的帮助文档:https://www.dnspod.cn/Support
在DNSPod自己的域名下添加一条A记录,地址就是Github Pages的服务IP地址:192.30.252.153
在域名注册商处修改DNS服务:去Godaddy修改Nameservers为这两个地址: f1g1ns1.dnspod.net、f1g1ns2.dnspod.net。
##配置和使用Github
git是版本管理的未来,他的优点我不再赘述,相关资料很多。推荐这本Git中文教程。
要使用Git,需要安装它的客户端,推荐在Linux下使用Git,会比较方便。下载地址在这里:http://code.google.com/p/msysgit/downloads/lis 。其他系统的安装也可以参考官方的安装教程。
安装完成后,还需要最后一步设置,在命令行输入:
$ git config --global user.name "Your Name"
$ git config --global user.email "email@example.com"
###检查SSH keys的设置
首先我们需要检查你电脑上现有的ssh key:
$ cd ~/.ssh如果显示“No such file or directory”,跳到第三步,否则继续。
###备份和移除原来的ssh key设置
因为已经存在key文件,所以需要备份旧的数据并删除:
ls
config id_rsa id_rsa.pub known_hosts
mkdir key_backup
cp id_rsa* key_backup
rm id_rsa*###生成新的SSH Key
输入下面的代码,就可以生成新的key文件,我们只需要默认设置就好,所以当需要输入文件名的时候,回车就好。
$ ssh-keygen -t rsa -C "邮件地址@youremail.com"
Generating public/private rsa key pair.
Enter file in which to save the key (/Users/ your_user_directory/.ssh/id_rsa):<回车就好>然后系统会要你输入加密串(Passphrase):
Enter passphrase (empty for no passphrase):<输入加密串>
Enter same passphrase again:<再次输入加密串>最后看到ssh key success,就成功设置ssh key了.
###添加SSH Key到GitHub
在本机设置SSH Key之后,需要添加到GitHub上,以完成SSH链接的设置。
用文本编辑工具打开id_rsa.pub文件,如果看不到这个文件,你需要设置显示隐藏文件。准确的复制这个文件的内容,才能保证设置的成功。
在GitHub的主页上点击设置按钮: github account setting
选择SSH Keys项,把复制的内容粘贴进去,然后点击Add Key按钮即可:
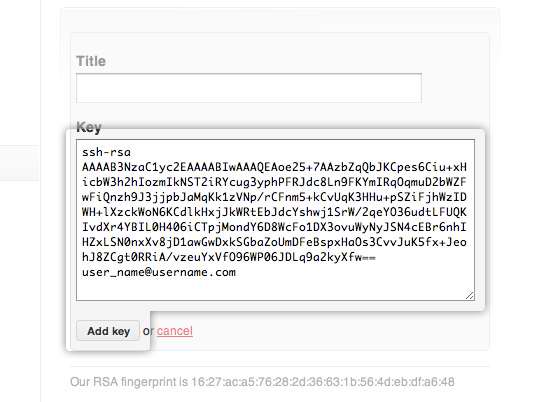
PS:如果需要配置多个GitHub账号,可以参看这个多个github帐号的SSH key切换,不过需要提醒一下的是,如果你只是通过这篇文章中所述配置了Host,那么你多个账号下面的提交用户会是一个人,所以需要通过命令git config --global --unset user.email删除用户账户设置,在每一个repo下面使用git config --local user.email '你的github邮箱@mail.com' 命令单独设置用户账户信息
###测试一下
可以输入下面的命令,看看设置是否成功,git@github.com的部分不要修改:
$ ssh -T git@github.com
如果是下面的反应:
The authenticity of host 'github.com (207.97.227.239)' can't be established.
RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48.
Are you sure you want to continue connecting (yes/no)?
不要紧张,输入yes就好,然后会看到:
Hi <em>username</em>! You've successfully authenticated, but GitHub does not provide shell access.
###设置你的账号信息
现在你已经可以通过SSH链接到GitHub了,还有一些个人信息需要完善的。
Git会根据用户的名字和邮箱来记录提交。GitHub也是用这些信息来做权限的处理,输入下面的代码进行个人信息的设置,把名称和邮箱替换成你自己的,名字必须是你的真名,而不是GitHub的昵称。
$ git config --global user.name "你的名字"
$ git config --global user.email "your_email@youremail.com"好了,你已经可以成功连接GitHub了。
##快速开始
###帐号注册
在创建博客之前,当然必须有GitHub的帐号,该帐号将用来创建项目,默认的域名username.github.com/projectName中的username也要用到这个帐号。
注意:下面涉及到的一些命令凡是更用户名和项目名有关的一律会用这里的username和projectName代替,注意替换 访问:http://www.github.com/ sign up for free的意思就是“免费注册登录”,注册你的username和邮箱,邮箱十分重要,GitHub上很多通知都是通过邮箱的。比如你的主页上传并构建成功会通过邮箱通知,更重要的是,如果构建失败的话也会在邮件中说明原因。
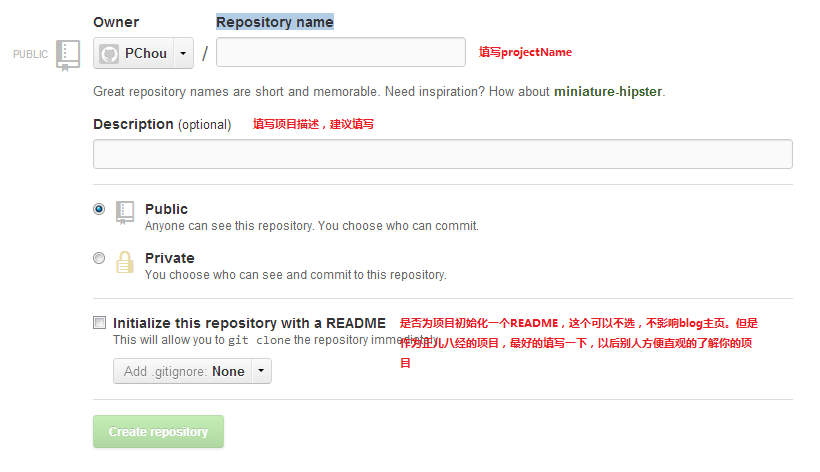
###创建项目仓库
在创建博客之前,还需要用已有的帐号创建一个项目,上面那个链接的projectName将是这里即将创建的项目名称。在Git中,项目被称为仓库(Repository),仓库顾名思义,当然可以包含代码或者非代码。将来我们的网页或者模板实际上都是保存在这个仓库中的。
登录后,访问https://github.com/new,创建仓库如下图:
创建了仓库后,我们就需要管理它,无论是管理本地仓库还是远程仓库都需要Git客户端。Git客户端实际上十分强大,它本身就可以offline的创建本地仓库,而本地仓库和远程仓库之间的同步也是通过Git客户端完成的。
这里省略了windows下安装和使用Git客户端的基本技巧,您应该已经掌握此技能了。虽然,您仍然可以按照本教程的指引完成一个简单的网站,但是后期的维护工作无论如何都不能少了这项技能。
下面的步骤假设您已经安装好了Git客户端,安装和使用技巧请参见:Git学习资源
###本地编辑及上传
在磁盘上创建一个目录,该目录与上面的项目名同名,在该目录下启用Git Bash命令行,并输入如下命令
$git init
该命令实际上是在该目录下初始化一个本地的仓库,会在目录下新建一个.git的隐藏文件夹,可以看成是一个仓库数据库。
创建一个没有父节点的分支gh-pages,并自动切换到这个分支上。
$git checkout --orphan gh-pages
在Git中,分支(branch)的概念非常重要,Git之所以强大,很大程度上就是因为它强大的分支体系。这里的分支名字必须是gh-pages,因为github规定,只有该分支中的页面,才会生成网页文件。
在该目录下手动创建如下文件和文件夹,最终形成这样的结构:
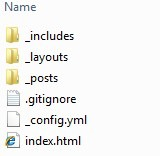
- _includes:默认的在模板中可以引用的文件的位置,后面会提到
- _layouts:默认的公共页面的位置,后面会提到
- _posts:博客文章默认的存放位置
- .gitignore:git将忽略这个文件中列出的匹配的文件或文件夹,不将这些纳入源码管理
- _config.yml:关于jekyll模板引擎的配置文件
- index.html:默认的主页
在_layouts目录下创建一个default.html,在其中输入如下内容,注意:文件本身要以UTF-8 without BOM的格式保存,以防止各种编码问题,建议使用notepad++或者VIM编辑
default.html
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
<title>一步步在GitHub上创建博客主页(2)</title>
</head>
<body>
</body>
</html>
编辑index.html
---
layout: default
title: test title
---
<p>Hello world!</p>
再次打开Git Bash,先后输入如下命令:
$ git add .
$ git commit -m "first post"
$ git remote add origin https://github.com/username/projectName.git
$ git push origin gh-pages据网友反应,如果是初次安装git的话,在commit的时候会提示需要配置username和email,请读者注意根据提示配置一下,至于username和email可以随便填
- 将当前的改动暂存在本地仓库
- 将暂存的改动提交到本地仓库,并写入本次提交的注释是”first post“
- 将远程仓库在本地添加一个引用:origin
- 向origin推送gh-pages分支,该命令将会将本地分支gh-pages推送到github的远程仓库,并在远程仓库创建一个同名的分支。该命令后会提示输入用户名和密码。
现在,你只需要稍等半分钟时间,访问http://username.github.com/projectName就可以看到生成的博客了
另外上面提到的,如果生成失败,Github会向你的邮箱发送一封邮件说明,请注意查收。
##域名扫盲
说实话,虽然明白什么是域名以及域名解析的原理,但是在实际的互联网环境中,域名的问题其实比理论上说的要复杂些。这里对一些概念稍作整理。
###A(Address)记录
是用来指定主机名(或域名)对应的IP地址记录。用户可以将该域名下的网站服务器指向到自己的web server上。同时也可以设置您域名的二级域名。
###CNAME
也被称为规范名字。这种记录允许您将多个名字映射到同一台计算机。 通常用于同时提供WWW和MAIL服务的计算机。例如,有一台计算机名为“host.mydomain.com”(A记录)。 它同时提供WWW和MAIL服务,为了便于用户访问服务。可以为该计算机设置两个别名(CNAME):WWW和MAIL。 这两个别名的全称就是“www.mydomain.com”和“mail.mydomain.com”。实际上他们都指向“host.mydomain.com”。 同样的方法可以用于当您拥有多个域名需要指向同一服务器IP,此时您就可以将一个域名做A记录指向服务器IP然后将其他的域名做别名到之前做A记录的域名上,那么当您的服务器IP地址变更时您就可以不必麻烦的一个一个域名更改指向了 只需要更改做A记录的那个域名其他做别名的那些域名的指向也将自动更改到新的IP地址上了。
###TTL
TTL值全称是“生存时间(Time To Live)”,简单的说它表示DNS记录在DNS服务器上缓存时间。要理解TTL值,请先看下面的一个例子:
假设,有这样一个域名myhost.cnMonkey.com(其实,这就是一条DNS记录,通常表示在abc.com域中有一台名为myhost的主机)对应IP地 址为1.1.1.1,它的TTL为10分钟。这个域名或称这条记录存储在一台名为dns.cnMonkey.com的DNS服务器上。
现在有一个用户键入一下地址(又称URL):http://myhost.cnMonkey.com 这时会发生什么呢?
该 访问者指定的DNS服务器(或是他的ISP,互联网服务商, 动态分配给他的)8.8.8.8就会试图为他解释myhost.cnMonkey.com,当然8.8.8.8这台DNS服务器由于没有包含 myhost.cnMonkey.com这条信息,因此无法立即解析,但是通过全球DNS的递归查询后,最终定位到dns.cnMonkey.com这台DNS服务器, dns.cnMonkey.com这台DNS服务器将myhost.cnMonkey.com对应的IP地址1.1.1.1告诉8.8.8.8这台DNS服务器,然有再由 8.8.8.8告诉用户结果。8.8.8.8为了以后加快对myhost.cnMonkey.com这条记录的解析,就将刚才的1.1.1.1结果保留一段时间,这 就是TTL时间,在这段时间内如果用户又有对myhost.cnMonkey.com这条记录的解析请求,它就直接告诉用户1.1.1.1,当TTL到期则又会重复 上面的过程。
###域名分级
子域名是个相对的概念,是相对父域名来说的。域名有很多级,中间用点分开。例如中国国家顶级域名CN,所有以 CN 结尾的域名便都是它的子域。例如:www.zzy.cn 便是 zzy.cn 的子域,而 zzy.cn 是 cn 的子域。
“二级域名”:目前有很多用户认为“二级域名”是自己所注册域名的下一级域名,实际上这里所谓的“二级域名”并非真正的“二级”,而应该称为“次级”(相对次级)
例如您注册的域名是abc.cn来说:CN为顶级域,abc.cn为二级域,www.abc.cn、mail.abc.cn、help.zzy.cn为三级域。
还有一些特殊的二级域被用来作顶级域使用,例如:com.cn、net.cn、org.cn、gov.cn(包括地区域名bj.cn、fj.cn等)。那么此时用户所注册的就应该是三级域了,例如114.com.cn。(备注:www.gov.cn实际上是以gov.cn为后缀的www域名,就是说如果您在域名Whois信息查询中输入gov.cn是查询不到注册信息的因为gov.cn是作为顶级域来使用的域名后缀,真正开放注册的是www.gov.cn)。然而当前有很多用户还是习惯地将可以允许用户注册的域名称为顶级域名,而所注册域名的下一级域名称为“二级域名”,其实从严格意义上来讲这是不对的,所以我们前面会说“子域名”、“二级域名”是相对的概念,准确的应该称为“次级域名”。
###域名购买
众所周知,域名是要购买的,国内用域名访问主机大概是要备案的,有些麻烦。所以现在很多人从国外的域名注册商那儿买域名,比如goddady。如果是新手想在国外买域名的话,最好准备一张VISA信用卡,并用paypal来支付(可以省手续费)。goddady现在也支持支付宝,支付起来也很方便。
###绑定域名到GitHub-Page
其实十分简单,假设我们购买了域名coolshell.info,想用coolshell.info访问你的站点http://username.github.com/projectname,你可以参考这个链接:Setting up a custom domain with Pages
在你的域名提供商那边,设置一条A记录:
colshell.info 204.232.175.78(注意:这个IP难保不会变,所以要及时关注上面这个链接中给出的IP,并及时更新A记录)。下面这个截图是goddady上的A记录配置:

然后在你的gh-pages分支的根目录中创建一个CNAME文件,其中只能有一行,就是coolshell.info,用Git客户端上传更改,大约等十几分钟就能生效了。
可以先ping一下coolshell.info,如果返回的IP地址更配置的A记录一样的话,说明域名已经注册好了,就等GitHub生效了。不过别急,你还需要把_config.yml中的baseurl设置如下
baseurl : /
或者是
baseurl :
这取决于你的模板如何引用baseurl,总之指向根目录就好了。
刚开始的时候我比较困惑的是,为什么A记录都指向的是同一个IP,GitHub是如何知道应该返回哪个用户的页面的。其实很简单,秘密就是上面提到的CNAME文件,GitHub应该会缓存所有gh-pages分支中的CNAME文件,用户对域名的请求被定向到GitHub住服务器的IP地址后,再根据用户请求的域名,判断对应哪个gh-pages,而且它会自动带上项目名,所以baseurl需要改为根目录。
##jekyll的安装
前几篇介绍了GitHub-Page的基本原理和使用方法,还介绍了如何将购买的域名绑定博客主页。然而,当需要正儿八经的将一个博客构建起来,不仅要知道如何上传我们的文件,还要能够高效的更好的设计博客。因此,必须能够在上传之前在本地完成测试;另一方面,完全靠html来编辑博客,显然工作量太大,随着博客越来越复杂,简直不可能维护,因此,需要用jekyll这个模板引擎来帮忙。本篇先介绍如何搭建一个本地的测试环境。
###更新
- 根据网友的反应,需要注意的是Ruby的版本和RubyDevKit的版本要对应,不要装错;
- 另外,目前新版的Ruby自带gem了,所以gem安装可以跳过;
- 由于国内的网络(你们懂的),gem官方的源基本上是没法用了,参考文中的链接,使用淘宝的镜像比较靠谱;
-
jekyll有一个问题,可能需要修改下面这个文件,否则会出现GBK错误
D:\Ruby193\lib\ruby\gems\1.9.1\gems\jekyll-1.2.1\lib\jekyll\convertible.rb将它改成self.content = File.read(File.join(base, name),:encoding => "utf-8")D:\Ruby193\lib\ruby\gems\1.9.1\gems\jekyll-1.2.1\lib\jekyll\tags\include.rb中的最后几行的地方改成File.read_with_options(file,:encoding => "utf-8") - 最新的jekyll修改了命令行参数,需使用如下命令行
jekyll serve --safe --watch - jekyll 1.4.3在windows下本地生成的时候可能会出现
'fileutils.rb:247:in mkdir Invalid argument'的错误 - jekyll 1.4.3在–watch参数的情况下可能会出现
'cannot load such file -- wdm (LoadError)'的错误,用gem安装wdm就好了: gem install wdm
###Ruby安装
jekyll本身基于Ruby开发,因此,想要在本地构建一个测试环境需要具有Ruby的开发和运行环境。在windows下,可以使用Rubyinstaller安装
ruby安装说明:http://www.ruby-lang.org/zh_cn/downloads/
ruby安装下载(windows):http://rubyinstaller.org/downloads/ windows的安装还是一如既往的“无脑”,不多说了。
如果想要快速体验ruby开发,可以参考:20分钟体验 Ruby
###RubyDevKit安装
从这个页面下载DevKit:http://rubyinstaller.org/downloads/
下载下来的是一个很有意思的sfx文件,如果你安装有7-zip吧,可以直接双击,它会自解压到你所选择的目录。
解压完成之后,用cmd进入到刚才解压的目录下,运行下面命令,该命令会生成config.yml。(这种安装方式让我想起了,linux下安装三步走config->make->make install中的config)
$ruby dk.rb init
config.yml文件实际上是检测系统安装的ruby的位置并记录在这个文件中,以便稍后使用。但上面的命令只针对使用rubyinstall安装的ruby有效,如果是其他方式安装的话,需要手动修改config.yml。我生成的config.yml文件内容如下:(注意路径用的是linux的斜杠方向)
# This configuration file contains the absolute path locations of all
# installed Rubies to be enhanced to work with the DevKit. This config
# file is generated by the 'ruby dk.rb init' step and may be modified
# before running the 'ruby dk.rb install' step. To include any installed
# Rubies that were not automagically discovered, simply add a line below
# the triple hyphens with the absolute path to the Ruby root directory.
#
# Example:
#
# ---
# - C:/ruby19trunk
# - C:/ruby192dev
#
---
- C:/Ruby193最后,执行如下命令,执行安装:
$ruby setup.rb
如果没有setup.rb的话,执行:
$ruby dk.rb install
###Rubygems
Rubygems是类似Radhat的RPM、centOS的Yum、Ubuntu的apt-get的应用程序打包部署解决方案。Rubygems本身基于Ruby开发,在Ruby命令行中执行。我们需要它主要是因为jekyll的执行需要依赖很多Ruby应用程序,如果一个个手动安装比较繁琐。jekyll作为一个Ruby的应用,也实现了Rubygems打包标准。只要通过简单的命令就可以自动下载其依赖。
gems下载地址:http://rubyforge.org/frs/?group_id=126
解压后,用cmd进入到解压后的目录,执行命令即可:
$ruby setup.rb
就像yum仓库一样,仓库本身有很多,如果希望加快应用程序的下载速度,特别绕过“天朝”的网络管理制度,可以选择国内的仓库镜像,taobao有一个:http://ruby.taobao.org/。配置方法这个链接里面很完全。
###安装jekyll
有了上面的基础,安装jekyll就十分轻松了,在此之前,建议国内用户换成淘宝服务器,速度更快:
$ sudo gem sources --remove http://rubygems.org/
$ sudo gem sources -a http://ruby.taobao.org/
执行下面gem命令即可全自动搞定:
$gem install jekyll
jekyll依赖的组件如下:
- directory_watcher
- liquid
- open4
- maruku
- classifier
测试jekyll服务
安装好之后就可以测试我们的环境了。用cmd进入到上一节我们创建的目录,执行下面命令:
$jekyll --server --safe
jekyll此时会在localhost的4000端口监听http请求,用浏览器访问http://localhost:4000/index.html,之前的页面出现了!
更新 jekyll最新的动态和文档现在可以在jekyllrb上找到
##jekyll介绍
在前几篇中,多多少少对jekyll有所涉及,在这篇中将带读者进一步了解jekyll以及模板引擎liquid。
jekyll是一个基于ruby开发的,专用于构建静态网站的程序。它能够将一些动态的组件:模板、liquid代码等构建成静态的页面集合,Github-Page全面引入jekyll作为其构建引擎,这也是学习jekyll的主要动力。同时,除了jekyll引擎本身,它还提供一整套功能,比如web server。我们用jekyll –server启动本地调试就是此项功能。读者可能已经发现,在启动server后,之前我们的项目目录下会多出一个_site目录。jekyll默认将转化的静态页面保存在_site目录下,并以某种方式组织。使用jekyll构建博客是十分适合的,因为其内建的对象就是专门为blog而生的,在后面的逐步介绍中读者会体会到这一点。但是需要强调的是,jekyll并不是博客软件,跟workpress之类的完全两码事,它仅仅是个一次性的模板解析引擎,它不能像动态服务端脚本那样处理请求。
更多关于jekyll请看这里
###jekyll是如何工作的
在jekyll解析你的网站结构前,需要确保网站目录像下面那样:
|-- _config.yml
|-- _includes
|-- _layouts
| |-- default.html
| |-- post.html
|-- _posts
| |-- 20011-10-25-open-source-is-good.html
| |-- 20011-04-26-hello-world.html
|-- _site
|-- index.html
|-- images
|-- css
|-- style.css
|-- javascripts
-
_config.yml:保存配置,该配置将影响jekyll构造网站的各种行为。
-
_includes:该目录下的文件可以用来作为公共的内容被其他文章引用,就跟C语言include头文件的机制完全一样,jekyll在解析时会对
{ % include file.ext %}标记扩展成对应的在_includes文件夹中的文件 -
_layouts:该目录下的文件作为主要的模板文件
-
_posts:文章或网页应当放在这个目录中,但需要注意的是,文章的文件名必须是YYYY-MM-DD-title
-
_site:上面提到过,这是jekyll默认的转化结果存放的目录
-
images:这个目录没有强制的要求,主要目的是存放你的资源文件,图片、样式表、脚本等。
###一个例子
完成一个例子总是最快的入门方式。
对于基于静态页面的网站,你显然不希望每篇文章都要写html、head等与文章本身无关的重复的东西,那么容易想到的是将这些东西作为模板提取出来,以便复用,_layouts文件夹中的文件可以作为这样的模板。现在我们在_layouts文件夹中创建一个模板文件,default.html:
default.html
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>My blog</title>
</head>
<body>
<!-- Blog Post --> <!-- Title -->
谈谈缓存和基本的缓存算法
纠错
04 Feb 2015
很久很久以前,在还没有缓存的时候……用户经常是去请求一个对象,而这个对象是从数据库去取,然后,这个对象变得越来越大,这个用户每次的请求时间也越来越长了,这也把数据库弄得很痛苦,他无时不刻不在工作。所以,这个事情就把用户和数据库弄得很生气,接着就有可能发生下面两件事情:
- 用户很烦,在抱怨,甚至不去用这个应用了(这是大多数情况下都会发生的)
- 数据库为打包回家,离开这个应用,然后,就出现了大麻烦(没地方去存储数据了)(发生在极少数情况下)
####上帝派来了缓存####
在几年之后,IBM(60年代)的研究人员引进了一个新概念,它叫“缓存”。
###什么是缓存?
通俗来说,缓存是“存贮数据(使用频繁的数据)的临时地方,因为取原始数据的代价太大了,所以我可以取得快一些。”
我们都听说过线程池、对象池,缓存可以认为是数据的池,这些数据是从数据库里的真实数据复制出来的,并且为了能别取回,被标上了标签(键 ID)。
{kind=link}
命中:
当客户发起一个请求(我们说他想要查看一个产品信息),我们的应用接受这个请求,并且如果是在第一次检查缓存的时候,需要去数据库读取产品信息。
如果在缓存中,一个条目通过一个标记被找到了,这个条目就会被使用、我们就叫它缓存命中。所以,命中率也就不难理解了。
Cache Miss:
但是这里需要注意两点:
1. 如果还有缓存的空间,那么,没有命中的对象会被存储到缓存中来。
2. 如果缓存慢了,而又没有命中缓存,那么就会按照某一种策略,把缓存中的旧对象踢出,而把新的对象加入缓存池。而这些策略统称为*替代策略*(缓存算法),这些策略会决定到底应该提出哪些对象。
存储成本:
当没有命中时,我们会从数据库取出数据,然后放入缓存。而把这个数据放入缓存所需要的时间和空间,就是存储成本。
索引成本:
和存储成本相仿。
失效:
当存在缓存中的数据需要更新时,就意味着缓存中的这个数据失效了。
替代策略:
当缓存没有命中时,并且缓存容量已经满了,就需要在缓存中踢出一个老的条目,加入一条新的条目,而到底应该踢出什么条目,就由替代策略决定。
最优替代策略:
最优的替代策略就是想把缓存中最没用的条目给踢出去,但是未来是不能够被预知的,所以这种策略是不可能实现的。但是有很多策略,都是朝着这个目前去努力。
缓存算法
没有人能说清哪种缓存算法优于其他的缓存算法
Least Frequently Used(LFU):
大家好,我是 LFU,我会计算为每个缓存对象计算他们被使用的频率。我会把最不常用的缓存对象踢走。
Least Recently User(LRU):
我是 LRU 缓存算法,我把最近最少使用的缓存对象给踢走。
我总是需要去了解在什么时候,用了哪个缓存对象。如果有人想要了解我为什么总能把最近最少使用的对象踢掉,是非常困难的。
浏览器就是使用了我(LRU)作为缓存算法。新的对象会被放在缓存的顶部,当缓存达到了容量极限,我会把底部的对象踢走,而技巧就是:我会把最新被访问的缓存对象,放到缓存池的顶部。
所以,经常被读取的缓存对象就会一直呆在缓存池中。有两种方法可以实现我,array 或者是 linked list。
我的速度很快,我也可以被数据访问模式适配。我有一个大家庭,他们都可以完善我,甚至做的比我更好(我确实有时会嫉妒,但是没关系)。我家庭的一些成员包括 LRU2 和 2Q,他们就是为了完善 LRU 而存在的。
Least Recently Used 2(LRU2):
我是 Least Recently Used 2,有人叫我最近最少使用 twice,我更喜欢这个叫法。我会把被两次访问过的对象放入缓存池,当缓存池满了之后,我会把有两次最少使用的缓存对象踢走。因为需要跟踪对象2次,访问负载就会随着缓存池的增加而增加。如果把我用在大容量的缓存池中,就会有问题。另外,我还需要跟踪那么不在缓存的对象,因为他们还没有被第二次读取。我比LRU好,而且是 adoptive to access 模式 。
Two Queues(2Q):
我是 Two Queues;我把被访问的数据放到 LRU 的缓存中,如果这个对象再一次被访问,我就把他转移到第二个、更大的 LRU 缓存。
我踢走缓存对象是为了保持第一个缓存池是第二个缓存池的1/3。当缓存的访问负载是固定的时候,把 LRU 换成 LRU2,就比增加缓存的容量更好。这种机制使得我比 LRU2 更好,我也是 LRU 家族中的一员,而且是 adoptive to access 模式 。
Adaptive Replacement Cache(ARC):
我是 ARC,有人说我是介于 LRU 和 LFU 之间,为了提高效果,我是由2个 LRU 组成,第一个,也就是 L1,包含的条目是最近只被使用过一次的,而第二个 LRU,也就是 L2,包含的是最近被使用过两次的条目。因此, L1 放的是新的对象,而 L2 放的是常用的对象。所以,别人才会认为我是介于 LRU 和 LFU 之间的,不过没关系,我不介意。
我被认为是性能最好的缓存算法之一,能够自调,并且是低负载的。我也保存着历史对象,这样,我就可以记住那些被移除的对象,同时,也让我可以看到被移除的对象是否可以留下,取而代之的是踢走别的对象。我的记忆力很差,但是我很快,适用性也强。
Most Recently Used(MRU):
我是 MRU,和 LRU 是对应的。我会移除最近最多被使用的对象,你一定会问我为什么。好吧,让我告诉你,当一次访问过来的时候,有些事情是无法预测的,并且在缓存系统中找出最少最近使用的对象是一项时间复杂度非常高的运算,这就是为什么我是最好的选择。
我是数据库内存缓存中是多么的常见!每当一次缓存记录的使用,我会把它放到栈的顶端。当栈满了的时候,你猜怎么着?我会把栈顶的对象给换成新进来的对象!
First in First out(FIFO):
我是先进先出,我是一个低负载的算法,并且对缓存对象的管理要求不高。我通过一个队列去跟踪所有的缓存对象,最近最常用的缓存对象放在后面,而更早的缓存对象放在前面,当缓存容量满时,排在前面的缓存对象会被踢走,然后把新的缓存对象加进去。我很快,但是我并不适用。
Second Chance:
大家好,我是 second chance,我是通过 FIFO 修改而来的,被大家叫做 second chance 缓存算法,我比 FIFO 好的地方是我改善了 FIFO 的成本。我是 FIFO 一样也是在观察队列的前端,但是很FIFO的立刻踢出不同,我会检查即将要被踢出的对象有没有之前被使用过的标志(1一个 bit 表示),没有没有被使用过,我就把他踢出;否则,我会把这个标志位清除,然后把这个缓存对象当做新增缓存对象加入队列。你可以想象就这就像一个环队列。当我再一次在队头碰到这个对象时,由于他已经没有这个标志位了,所以我立刻就把他踢开了。我在速度上比 FIFO 快。
CLock:
我是 Clock,一个更好的 FIFO,也比 second chance 更好。因为我不会像 second chance 那样把有标志的缓存对象放到队列的尾部,但是也可以达到 second chance 的效果。
我持有一个装有缓存对象的环形列表,头指针指向列表中最老的缓存对象。当缓存 miss 发生并且没有新的缓存空间时,我会问问指针指向的缓存对象的标志位去决定我应该怎么做。如果标志是0,我会直接用新的缓存对象替代这个缓存对象;如果标志位是1,我会把头指针递增,然后重复这个过程,知道新的缓存对象能够被放入。我比 second chance 更快。
Simple time-based:
我是 simple time-based 缓存算法,我通过绝对的时间周期去失效那些缓存对象。对于新增的对象,我会保存特定的时间。我很快,但是我并不适用。
Extended time-based expiration:
我是 extended time-based expiration 缓存算法,我是通过相对时间去失效缓存对象的;对于新增的缓存对象,我会保存特定的时间,比如是每5分钟,每天的12点。
Sliding time-based expiration:
我是 sliding time-based expiration,与前面不同的是,被我管理的缓存对象的生命起点是在这个缓存的最后被访问时间算起的。我很快,但是我也不太适用。
其他的缓存算法还考虑到了下面几点:
成本:如果缓存对象有不同的成本,应该把那些难以获得的对象保存下来。
容量:如果缓存对象有不同的大小,应该把那些大的缓存对象清除,这样就可以让更多的小缓存对象进来了。
时间:一些缓存还保存着缓存的过期时间。电脑会失效他们,因为他们已经过期了。
根据缓存对象的大小而不管其他的缓存算法可能是有必要的。
在这一部分中,我们来看看如何实现这些著名的缓存算法。以下的代码只是示例用的,如果你想自己实现缓存算法,可能自己还得加上一些额外的工作。
Random Cache
我是随机缓存,我随意的替换缓存实体,没人敢抱怨。你可以说那个被替换的实体很倒霉。通过这些行为,我随意的去处缓存实体。我比 FIFO 机制好,在某些情况下,我甚至比 LRU 好,但是,通常LRU都会比我好。
看看缓存元素(缓存实体)
public class CacheElement
{
private Object objectValue;
private Object objectKey;
private int index;
private int hitCount; // getters and setters
}
这个缓存实体拥有缓存的key和value,这个实体的数据结构会被以下所有缓存算法用到。
缓存算法的公用代码
public final synchronized void addElement(Object key, Object value)
{
int index;
Object obj;
// get the entry from the table
obj = table.get(key);
// If we have the entry already in our table
// then get it and replace only its value.
obj = table.get(key);
if (obj != null)
{
CacheElement element;
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}
}
上面的代码会被所有的缓存算法实现用到。这段代码是用来检查缓存元素是否在缓存中了,如果是,我们就替换它,但是如果我们找不到这个 key 对应的缓存,我们会怎么做呢?那我们就来深入的看看会发生什么吧!
看看随机缓存的实现
public final synchronized void addElement(Object key, Object value)
{
int index;
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element;// Just replace the value.
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}// If we haven't filled the cache yet, put it at the end.
if (!isFull())
{
index = numEntries;
++numEntries;
}
else { // Otherwise, replace a random entry.
index = (int) (cache.length * random.nextFloat());
table.remove(cache[index].getObjectKey());
}
cache[index].setObjectValue(value);
cache[index].setObjectKey(key);
table.put(key, cache[index]);
}
看看FIFO缓算法的实现
public final synchronized void addElement(Objectkey, Object value)
{
int index;
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element; // Just replace the value.
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}
// If we haven't filled the cache yet, put it at the end.
if (!isFull())
{
index = numEntries;
++numEntries;
}
else { // Otherwise, replace the current pointer,
// entry with the new one.
index = current;
// in order to make Circular FIFO
if (++current >= cache.length)
current = 0;
table.remove(cache[index].getObjectKey());
}
cache[index].setObjectValue(value);
cache[index].setObjectKey(key);
table.put(key, cache[index]);
}
看看LFU缓存算法的实现
public synchronized Object getElement(Object key)
{
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element = (CacheElement) obj;
element.setHitCount(element.getHitCount() + 1);
return element.getObjectValue();
}
return null;
}
public final synchronized void addElement(Object key, Object value)
{
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element; // Just replace the value.
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}
if (!isFull())
{
index = numEntries;
++numEntries;
}
else
{
CacheElement element = removeLfuElement();
index = element.getIndex();
table.remove(element.getObjectKey());
}
cache[index].setObjectValue(value);
cache[index].setObjectKey(key);
cache[index].setIndex(index);
table.put(key, cache[index]);
}
public CacheElement removeLfuElement()
{
CacheElement[] elements = getElementsFromTable();
CacheElement leastElement = leastHit(elements);
return leastElement;
}
public static CacheElement leastHit(CacheElement[] elements)
{
CacheElement lowestElement = null;
for (int i = 0; i < elements.length; i++)
{
CacheElement element = elements[i];
if (lowestElement == null)
{
lowestElement = element;
}
else {
if (element.getHitCount() < lowestElement.getHitCount())
{
lowestElement = element;
}
}
}
return lowestElement;
}
最重点的代码,就应该是 leastHit 这个方法,这段代码就是把
hitCount 最低的元素找出来,然后删除,给新进的缓存元素留位置。
看看LRU缓存算法实现
private void moveToFront(int index)
{
int nextIndex, prevIndex;
if(head != index)
{
nextIndex = next[index];
prevIndex = prev[index];
// Only the head has a prev entry that is an invalid index
// so we don't check.
next[prevIndex] = nextIndex;
// Make sure index is valid. If it isn't, we're at the tail
// and don't set prev[next].
if(nextIndex >= 0)
prev[nextIndex] = prevIndex;
else
tail = prevIndex;
prev[index] = -1;
next[index] = head;
prev[head] = index;
head = index;
}
}
public final synchronized void addElement(Object key, Object value)
{
int index;Object obj;
obj = table.get(key);
if(obj != null)
{
CacheElement entry;
// Just replace the value, but move it to the front.
entry = (CacheElement)obj;
entry.setObjectValue(value);
entry.setObjectKey(key);
moveToFront(entry.getIndex());
return;
}
// If we haven't filled the cache yet, place in next available
// spot and move to front.
if(!isFull())
{
if(_numEntries > 0)
{
prev[_numEntries] = tail;
next[_numEntries] = -1;
moveToFront(numEntries);
}
++numEntries;
}
else { // We replace the tail of the list.
table.remove(cache[tail].getObjectKey());
moveToFront(tail);
}
cache[head].setObjectValue(value);
cache[head].setObjectKey(key);
table.put(key, cache[head]);
}
这段代码的逻辑如 LRU算法 的描述一样,把再次用到的缓存提取到最前面,而每次删除的都是最后面的元素。
结论
我们已经看到 LFU缓存算法 和 LRU缓存算法的实现方式,至于如何实现,采用数组还是 LinkedHashMap,都由你决定,不够我一般是小的缓存容量用数组,大的用 LinkedHashMap。
1.OSCache
OSCache是个一个广泛采用的高性能的J2EE缓存框架,OSCache能用于任何Java应用程序的普通的缓存解决方案。 OSCache有以下特点:缓存任何对象,你可以不受限制的缓存部分jsp页面或HTTP请求,任何java对象都可以缓存。拥有全面的API–OSCache API给你全面的程序来控制所有的OSCache特性。永久缓存–缓存能随意的写入硬盘,因此允许昂贵的创建(expensive-to-create)数据来保持缓存,甚至能让应用重启。支持集群–集群缓存数据能被单个的进行参数配置,不需要修改代码。缓存记录的过期–你可以有最大限度的控制缓存对象的过期,包括可插入式的刷新策略(如果默认性能不需要时)。
2.Java Caching system
JSC(Java Caching system)是一个用分布式的缓存系统,是基于服务器的java应用程序。它是通过提供管理各种动态缓存数据来加速动态web应用。 JCS和其他缓存系统一样,也是一个用于高速读取,低速写入的应用程序。动态内容和报表系统能够获得更好的性能。如果一个网站,有重复的网站结构,使用间歇性更新方式的数据库(而不是连续不断的更新数据库),被重复搜索出相同结果的,就能够通过执行缓存方式改进其性能和伸缩性。
3.EHCache
EHCache 是一个纯java的在进程中的缓存,它具有以下特性:快速,简单,为Hibernate2.1充当可插入的缓存,最小的依赖性,全面的文档和测试。
4.JCache
JCache是个开源程序,正在努力成为JSR-107开源规范,JSR-107规范已经很多年没改变了。这个版本仍然是构建在最初的功能定义上。
5.ShiftOne
ShiftOne Java Object Cache是一个执行一系列严格的对象缓存策略的Java lib,就像一个轻量级的配置缓存工作状态的框架。
6.SwarmCache
SwarmCache是一个简单且有效的分布式缓存,它使用IP multicast与同一个局域网的其他主机进行通讯,是特别为集群和数据驱动web应用程序而设计的。SwarmCache能够让典型的读操作大大超过写操作的这类应用提供更好的性能支持。 SwarmCache使用JavaGroups来管理从属关系和分布式缓存的通讯。
7.TreeCache / JBossCache
JBossCache是一个复制的事务处理缓存,它允许你缓存企业级应用数据来更好的改善性能。缓存数据被自动复制,让你轻松进行JBoss服务器之间的集群工作。JBossCache能够通过JBoss应用服务或其他J2EE容器来运行一个MBean服务,当然,它也能独立运行。 JBossCache包括两个模块:TreeCache和TreeCacheAOP。 TreeCache –是一个树形结构复制的事务处理缓存。TreeCacheAOP –是一个“面向对象”缓存,它使用AOP来动态管理POJO(Plain Old Java Objects) 注:AOP是OOP的延续,是Aspect Oriented Programming的缩写,意思是面向方面编程。
8.WhirlyCache
Whirlycache是一个快速的、可配置的、存在于内存中的对象的缓存。它能够通过缓存对象来加快网站或应用程序的速度,否则就必须通过查询数据库或其他代价较高的处理程序来建立。
本作品由 Lippi.OuYang 创作,采用 CC BY-NC-SA 3.0 许可协议 进行许可。
-
Volley源码分析
Aug 27, 2015 -
Hibernate缓存配置笔记
Jul 24, 2015 -
Java Lambda简明教程
Jun 3, 2015 -
Java虚拟机简介
Apr 18, 2015 -
优化java代码建议(1)
Apr 12, 2015 -
谈谈缓存和基本的缓存算法
Feb 4, 2015 -
谈谈如何提高web服务器并发性能
Dec 5, 2014 -
java中内部类
Nov 14, 2014 -
java同步容器与并发容器
Nov 8, 2014 -
关于返回 Null 值的问题
Sep 18, 2014 -
为什么 jdk 中把 String 类设计成 final
Aug 29, 2014 -
java编程的78条黄金法则
Aug 16, 2014 -
java并发和多线程
Aug 2, 2014 -
Android UI线程和子线程、Service通信
Jul 19, 2014 -
从android.os.NetworkOnMainThreadException引发的思考
Jul 18, 2014 -
Java编程Tips
Jun 18, 2014 -
在雨中
Jun 15, 2014
</body>
<html>
default.html包含了每个html都需要的一些标记,以及一个个liquid标记。{ { … }}是liquid中用来表示“内容”的标记,其中的对象在解析时会被替换成文件到页面中
content:表示在这里的地方用子页面的内容替换。
现在我们来实现一个主页,在根目录下,创建一个index.html
index.html
---
layout: default
---
<h1>Hello jekyll</h1>
<p>This is the index page</p>
除了普通的html标记外,开头这一段称为YAML格式,以一行“—”开头,一行“—”结尾,在虚线的中间以key-value的形式对一些全局变量进行赋值。
layout变量表示该文章应当使用_layouts/default这个文件作为父模板,并将index.html中的内容替换父模板中的{ { content }}标记。
在根目录中启动jekyll –server,并访问http://localhost:4000/index.html,你将得到下面页面
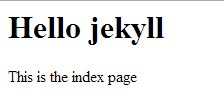
该页面的Html源码如下,可以看到,index.html中的内容替换了default.html中的{ { content }}
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>My blog</title>
</head>
<body>
<h1>Hello jekyll</h1>
<p>This is the index page</p>
</body>
<html>
现在请观察一下_site中的index.html,就是上面的Html代码!OK,现在你明白jekyll的工作方式了吧,它仅仅一次性的完成静态页面的转化,其余的事情全都交给普通的web server了!
需要注意的是,如果你失败了,请确保你的文件都是UTF-8 without BOM的格式。
在windows中,为了甄别UTF-8编码格式的文本文件,默认会在文件头插入两个字节的标识,被称为BOM。事实证明这是个“歪门邪道”,jekyll不识别这种特殊的标记,所以可以使用Notepad++或其他的工具将UTF-8编码文件开头的BOM去掉。
###第一篇文章
现在我们来创建一篇博客文章,并在index.html页面添加文章的链接。
在 _posts目录下创建2014-06-21-first-post.html
2014-06-21-first-post.html
---
layout: default
title: my first post
---
<h1>利用github-pages建立个人博客</h1>
<p>This is my first post.Click the link below to go back to index:</p>
<a href="/index.html">Go back</a>
修改index.html
index.html
---
layout: default
---
<h1>Hello jekyll</h1>
<p>This is the index page</p>
<p>My post list:</p>
最终效果如下:
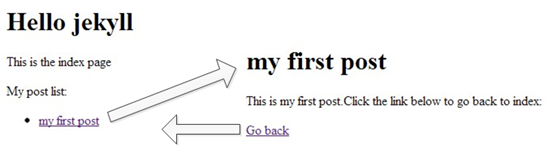
这个是略微复杂的例子,这里涉及到两个主要的对象
- site:全局站点对象。比如site.posts返回当前站点所有在_post目录下的文章,上面的例子结合for循环来罗列所有的文章
- page:文章对象。比如page.url将返回page对象的url,上面的例子用该对象和属性返回了文章的链接 另外要补充的是site.baseurl,该值就是我们在_config.yml中配置的baseurl啦!
这些对象被称为“模板数据API”,更多API文档请参见这里
###liquid
liquid是jekyll底层用于解析的引擎,我们用到的{ { .. }}亦或是{ % … %}标记其实是靠liquid去解析的。本节将详细介绍liquid的使用。
liquid包含两种标记,理解他们的机理是十分重要的:
{ { .. }}:输入标记,其中的内容将被文本输出
{ % … %}:操作标记,通常包含控制流代码
例如:
Sorry, you are too young
另外liquid还包含一种叫filter的机制。这是种对输出标记的扩展,通过它可以对输出标记中的内容进行更细致的处理,例如:
Hello TOBI
Hello tobi has 4 letters!
Hello 2017 Aug
返回字符串大写的结果:TOBI 返回字符串的长度:4 将当前时间格式化输出 liquid内置了一些filter,并且该机制可以被扩展,jekyll便扩展了liquid的filter。
更多关于liquid的使用方法,请参见这里
更多关于jekyll对liquid的扩展,请参见这里
##样式、分类、标签
在前一篇中我们实际使用jekyll做了一个略微“复杂”的模板。并用它生成了站点。但是这样的blog显然太粗糙了,别说不能吸引别人了,自己都看不下去啊。作为自己的“门户”,当然要把美化工作放在第一位啦。
网站的美观十分重要,这当然要依靠CSS咯。因为完全基于静态页面,所以没有现成的动态模板可以使用,我们只能手写CSS了,这里不介绍CSS了,因为这是设计师的范畴了,屌丝程序员搞不来了。我的blog的样式是从网上找过来改的。
从功能的角度blog除了文章以外,对文章的分类、标签、归档都是主流的功能。
分类和标签功能是jekyll的yaml-format的内置功能,在每篇文章上方可以设置:这里需要注意的是如果多个分类或者tag的话,用逗号分隔,并且要紧跟一个空格。分类可以任意添加,Jekyll在解析网站的时候会统计所有的分类,并放到site.categories中;换句话说,不能脱离文章而设置分类。
---
layout: default
title: Title
description: 这里的description是自定义属性。
categories: [web-build]
tags: [github-page, jekyll, liquid]
---
下面是本站罗列分类的代码,供大家参考
<div id="categories-3" class="left">
<h3>Categories</h3>
<ul>
<li class="cat-item cat-item-6">
<a href="/categories/java.html">java</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/c.html">c</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/programming.html">programming</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/jekyll.html">jekyll</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/other.html">other</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/reprints.html">reprints</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/Android.html">Android</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/web.html">web</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/book.html">book</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/algorithm.html">algorithm</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/c/c++.html">c/c++</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/android.html">android</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/Gradle.html">Gradle</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/lambda.html">lambda</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/gradle.html">gradle</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/Latex.html">Latex</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/Unix/Linux.html">Unix/Linux</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/Git.html">Git</a></li>
<li class="cat-item cat-item-6">
<a href="/categories/hi.html">hi</a></li>
</ul>
</div>
注意到分类的url链接,这里的categories目录以及其中的html不会自动生成,需要手动添加的,也就是说每增加一个分类,都需要在categories下添加一个该分类的html。当然你可以选择其他目录,甚至考虑其他解决方案,不过我还没想到更简单的方法。Tag的处理方式类似,这里就省略了。
推荐大家下载jekyll原作者推荐的简单例子来学习:
$git clone https://github.com/plusjade/jekyll-bootstrap.git
下载的目录里面是一个完整的网站,可以使用我们本地的jekyll –server启动。另外,作者的网站:http://jekyllbootstrap.com/
###代码高亮
参考Jekyll官网文档里Code snippet highlighting一节。玩颜色魔法的大魔术师是Pygments。
###安装Python Pygments
Ubtuntu下:sudo apt-get install python-pygments
###设置代码高亮的样式
通过下面的命令可以查看当前支持的样式 from pygments.styles import STYLE_MAP STYLE_MAP.keys() 输出: [‘monokai’, ‘manni’, ‘rrt’, ‘perldoc’, ‘borland’, ‘colorful’, ‘default’, ‘murphy’, ‘vs’, ‘trac’, ‘tango’, ‘fruity’, ‘autumn’, ‘bw’, ‘emacs’, ‘vim’, ‘pastie’, ‘friendly’, ‘native’]
###生成指定样式的css文件
pygmentize -S native -f html > pygments.css
将生成的css文件拷贝到主题的css目录下,如:
%github pages project folder%\assets\themes\twitter\css\引入default.html中引入css文件:
// default目录如
%github pages project folder%\includes\themes\twitter\
// 引入如下代码
<link href='/css/pygments.css' rel="stylesheet" media="all">
在文章中高亮代码:
public class HelloWorld {
public static void main(String args[]) {
System.out.println("Hello World!");
}
}
###给文章添加目录
如你所见,我的这个博客里,稍长点的文章,都会生成目录树(Table of Content),并且配合有Bootstrap的affix、ScrollSpy 效果。同样地,在Jekyll构建的静态博客上,我一样想生成目录树。 Jekyll的Plugins页面中有提到一个插件 jekyll-toc-generator,但其实没有必要使用插件,因为 Jekyll 的 Markdown 渲染器 kramdown 已经具备这个功能。我们只需要启用它即可。
启用 kramdown
打开 _config.yml 文件,确保以下一行存在: markdown: kramdown
生成 TOC
接下来是在文章中标识 toc 的生成位置: * 目录 {:toc} # 陈三 ## 陈三的博客
- 请注意,
* 目录这一行是必需的,它表示目录树列表,至于星号后面写什么请随意 - 如果要把某标题从目录树中排除,则在该标题的下一行写上
{:.no_toc} - 目录深度可以通过 config.yml 文件中添加
toc_levels选项来定制,默认为1..6,表示标题一至标题六全部渲染 - 默认生成的目录列表会添加 id 值
markdown-toc,我们可以自定义 id 值,比如 {:toc #chen},生成的目录列表添加的 id 将会是 chen。
###评论功能
静态的网站不可能自己存放评论,于是只能考虑外挂评论了,查了一下比较靠谱和广泛的就是DISQUS了; Disqus是一个社会化的评论解决方案,请允许我使用这个烂透了的词,调用它的接口非常简单,在自己的页面加载他的一段JS代码即可,如果别人注册了Disqus,那么就可以方便的留言,交流,一处登录,处处方便,而且Disqus也提供了一些spam等策略,不用自己操心了,并且可以和一些现有的博客系统很好的转换对接。越来越多的网站开始使用Disqus的服务了,这是一个非常不错的趋势,Jekyll配合Disqus实在是完美了。我别无所求了。
点击 ,在下面的页面中填写相关的信息,注意先在右侧注册登录信息,然后再在左侧增加一个站点:
,在下面的页面中填写相关的信息,注意先在右侧注册登录信息,然后再在左侧增加一个站点:
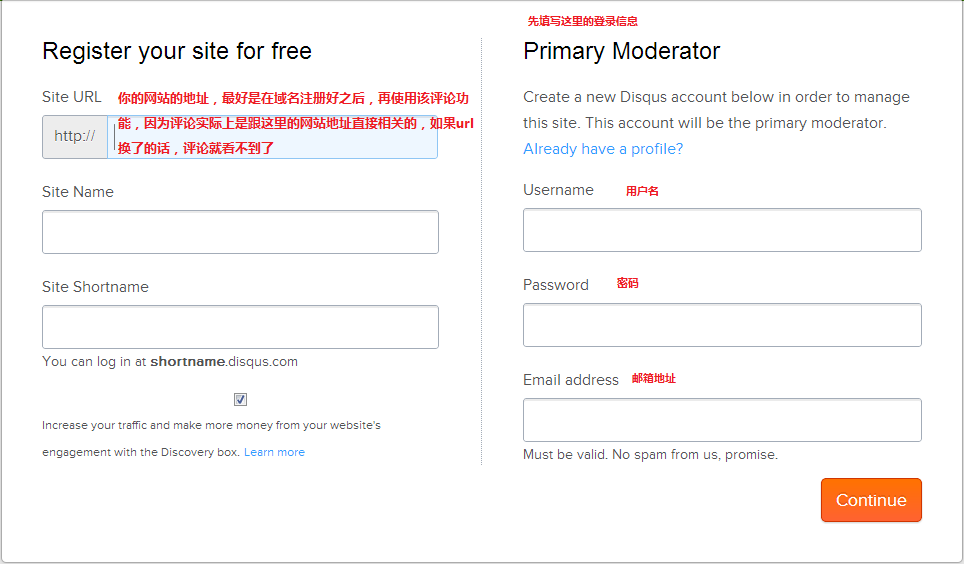
填写完成后点击“Continue”,在接下来的页面中选择Universal Code,然后根据提示完成接下来的操作,后面的操作就十分简单了:主要就是把产生的脚本文件复制到你的站点页面中即可。
DISQUS还有一个Dashboard,可以用来管理评论,这里就不再详述了。最后的效果就是本blog文章下方的评论咯,还是挺好看的,国内的还有个多说的评论引擎,支持国内的各大网站帐号。
###站内搜索
blog当然不能缺少站内搜索功能。主流的站内搜索都是主流的搜索引擎提供的。作为一个google控,当然必须选择google啊。当然你必须拥有一个google帐号。
google的站内搜索叫:custome search engine:http://www.google.com/cse
创建一个自定义搜索与添加评论类似只要三步:
- 填写自定义搜索的名字、描述、语言、站点信息,这些信息中唯一需要注意的是站点信息,建议使用mydomain.com作为搜索范围,因为这样的话,会自动转化成.mydomain.com/,能包含全站的内容
- 选择样式和尝试搜索。尝试搜索有时不能成功,但是不要紧
- 将生成脚本写到网页中
这时,可能搜索功能仍然无法使用,尤其是你的网站没有什么名气,也没有什么外链。因为google的爬虫不可能很快的抓到你的网站。但这里有个技巧可以让你的网站立刻被google收录(姑且不论排名),那就是google的Webmaster Tools工具,该工具是免费的,而且还集成了站点流量统计功能,十分强大。
进入地址:https://www.google.com/webmasters/tools/home
 它会要你认证你对网站的所有权,下载一个HTML文件,把它上传到你的网站上,
设置完成之后基本上立刻就生效了,无需等待一天。
它会要你认证你对网站的所有权,下载一个HTML文件,把它上传到你的网站上,
设置完成之后基本上立刻就生效了,无需等待一天。
认证成功后,进入sitemaps网站,在下面填入你的网站后点击start,
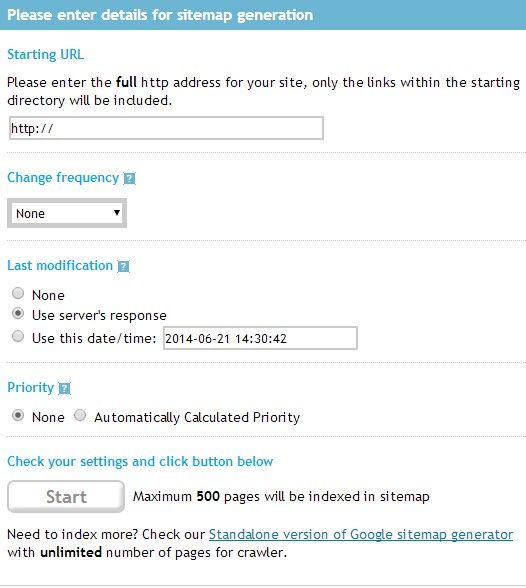 接下来下载sitemap文件,把它上传到你的域名根目录,
打开Optimization->Sitemaps,点击Add/TEST SITEMAP,输入指向你的站点的sitemap地址,本博客的sitemap是:http://coolshell.info/sitemap.xml,过几分钟就看到下面的结果:
!
接下来下载sitemap文件,把它上传到你的域名根目录,
打开Optimization->Sitemaps,点击Add/TEST SITEMAP,输入指向你的站点的sitemap地址,本博客的sitemap是:http://coolshell.info/sitemap.xml,过几分钟就看到下面的结果:
!
{kind=link}
sitemap是网站所有链接的集合,最简单的sitemap可以是一个文本文件,其中只存放你网站的所有可用资源的链接,这有利于搜索引擎收录你的网站内容。复杂的sitemap还可以利用sitemap的专用格式来标注资源的形式,更多关于sitemap可以参考:http://www.sitemaps.org/ 完成站点认证和sitemap测试后,我们回到自定义搜索的页面,进入到control panel->Indexing,在其中使用sitemap来迫使google索引你的网站。这样,你的网站就算被google收录了。
至于我们的站内搜索应该是可以用的了,试试本站点上方的搜索就知道啦~
###站点统计
这里介绍的站点统计是google的analytics,analytics的使用十分简单,同样的原理,利用注入脚本来实现流量统计的外挂,统计功能十分强大,谁用谁知道。这里就不再唠叨了。。
##GoDaddy & DNSPod
GoDaddy是一家非常不错的域名注册商,良好的用户体验,飞快的生效速度,给力的优惠码,也支持支付宝,永远不用担心国内那些流氓厂商的流氓行为,注册了域名,就可以放心不会被别人抢走。在Godaddy注册域名是一件很简单的事情,按照提示走就完全没有问题,唯一需要动脑筋的可能是,你要想一个既有个人标识,又没有被别人注册的域名了。
Godaddy一切都很完美,直到遇到了GFW,原因你肯定懂。前段时间推上风传Godaddy的DNS服务器被墙,导致域名不能解析,看起来好像自己的站被墙了一样,这个确实是个闹心的事情,还好国内有DNS服务的替代产品,而且做得还非常的不错,也是免费的,功能强大,速度快,不用担心被和谐,所以隆重推荐DNSPod给大家,可以试用一下,把DNS服务迁移到DNSPod来,解决后顾之忧,配置比较简单,不懂的可以等我后面的博客啦,哈。
##GitHub & Jekyll
GitHub是一个非常优秀的产品,爆发式的增长,各大优质开源软件的蜂涌而至,只能说明人们太需要他了。Social Coding是他的Slogan,产品的设计确实解决了很多代码交流的难题,让世界更平,让交流更畅,关于Git的学习,大家可以移步这里Pro Git中文版,这也是一个本身就在Github维护的一个项目,高质量的翻译了Git入门书,讲解详细,是学习Git的好资料。
GitHub是一个伟大的产品,GitHub Pages是他伟大的一部分,GitHub Pages基于Jekyll博客引擎,当我深入的研究了他之后,我深深的想给Jekyll的作者一个拥抱,列举一下Jekyll的优点:
- 可以单独放在自己的服务器上,他也是GitHub Pages的基础,质量可靠
- 将博客最重要的功能抽取出来,去除了WordPress的复杂、烦躁的东西,一切都是清晰可控的
- 可以方便的使用Markdown等其他标记语言
- Jekyll是完美的
写到这里,基本的点已经介绍完毕,现在介绍下怎么获取别人的博客模板来建立自己的博客。
获取并修改别人的博客
Jekyll官方建立了一个页面,里面有许多的模板可供参考。接下来我们就要奉行“拿来主义”了,将别人的模板为我们所用。
我自己用了Yukang’s Page</a>,他采用了一个叫做twitter的Jekyll Bootstrap的模板。下面假设你已经安装了git,我们把他人的网站代码clone下来,为了举例方便,还是选取了Yukang’s Page:
git clone https://github.com/chenyukang/chenyukang.github.com.git
然后删去别人的.git文件夹:
rm -rf .git
接着,我们参考jekyll的文件目录,可以把他人的博客删去,并且做一些小的调整。接下来,我们把改头换面的博客上传到自己的GitHub帐号中去。一般情况下,假设你的帐号名是USERNAME,你需要建一个名为USERNAME.github.io的帐号,分支为master。这样,在你将本地的网站push上去之后,不到10分钟,访问USERNAME.github.io,就可以看到你新鲜出炉的网站了:
git init
git add -A
git commit -m "first commit"
git remote add origin https://github.com/USERNAME/USERNAME.github.io.git
git push -u origin master
Git博大精深,我还没有熟练掌握。具体的命令可以参考下面一些参考资料:
-
入门:git - 简易指南
如果你想要在push之前就在本地预览一下网站,可以使用
jekyll serve --watch
命令。默认设置下,可以在浏览器中访问localhost:4000预览。详细情况请点击这里。
那么,我们如何撰写新的博客呢?下面,我们隆重推出Markdown。
##Markdown语法
根据维基百科上的介绍
Markdown 是一种轻量级标记语言,创始人为约翰·格鲁伯(John Gruber)和亚伦·斯沃茨(Aaron Swartz)。
想到Aaron Swartz已经故去,不禁一阵伤感。
Markdown的介绍有许多,个人推荐:
-
另一份入门文档:Markdown Cheatsheet
-
kramdown使用心得:Kramdown notes
备注:如何在Markdown中写注释呢?这里提供了最原始的一种解决方法:
看来在Markdown文件里写注释的唯一方法就是用<!– –>了,好吧。